In Ruby Performance: What a difference the compiler makes we saw how ruby performance on Windows benefits from the newer mingw compiler.
The measurements are done using our current build system with our production code. That’s ~36 MB (37.331.657 bytes at the time of writing) of sources and configuration files to parse and compile. After changing RubyInstaller versions the full build was still taking four to five minutes.
I’ll make a small parenthesis here to remark that the previous Dell Latitude series (the E64* and E65*) have huge performance issues. Identical laptops with identical software deliver wildly different numbers:
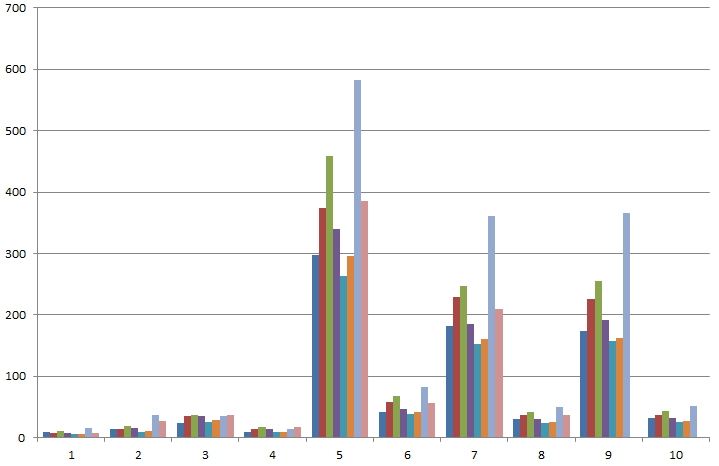
The Y axis is seconds. Each color is a different laptop and the ten clusters represent our ten most used rake tasks.
Astonishing in the above graph is that both the fastest as well as the second slowest time are from identical laptops (E6510 Latitudes). The slowest laptop is a E6410 Latitude which exhibits serious overheating.
To return from the brink of hardware apoplexy, the full build was still slow for our tastes. At this point the code is clean and very, very DRY. A few experiments with minimizing Rake::Task look-ups, cached Rake::FileList instances etc. showed exactly 0 improvement.
I like to think that that means there is nothing more to do to streamline the logic but it probably means that I have reached the end of my optimizing skillz. In line with the “reduce disk I/O” mantra, we started looking at the places were we interact heavily with the operating system.
File reads and writes from within Ruby we already had under control, but what about all those commands we delegated to the shell?
Rake#sh allows you to shell out for a command and conveniently raises an exception when the exit code of that command is <>0. When providing a single string it will spawn a full shell (on Windows that means cmd.exe) while when providing an array of strings it will use Kernel#system semantics.
Turns out (doh!) that using Kernel#system is a tick faster. It gets buried in the noise if you only do a couple but when compiling we tend to do two to three calls to Rake#sh per library (compiler, assembler and archiver). At about 130 libraries switching from sh(String) to sh(Array) gave us a 7% performance boost which translates to builds faster by >20 seconds.
Short of mangling my clean dependency structures and hacking the code to bits (meaning I will be damned to an eternity of maintaining it by myself) I can’t see how I can improve performance further.
Fortunately all of this currently happens on normal hard disks and the order for an SSD has already been placed, so there is still hope. After that, parallel is the only way to go.
I have now actually spent almost a full four weeks in a measure-analyze-refactor loop. I’ve gained three insights as far as performance optimization is concerned:
-
Keeping the code DRY with clean abstractions and proper design is infinitely more useful and productive than hacking tricks for performance’s sake. None of the tricks I used made any difference while they made the code a lot harder to read and maintain. Refactoring for DRYness and testability on the other hand proved a boon: It isolated the suspects, allowed granular benchmarking and made experiments a hell of a lot easier.
-
Measure, measure, measure. It doesn’t matter what you’ve read or what you think looks faster in your source files. Between the source and it’s output lie several layers (interpreter, shell, operating system) over which you have little or no control. Unless you see those numbers going down no change is worth committing.
-
Optimizing performance is HARD and it takes TIME. Look for the usual suspects (disk I/O I’m looking at you) and avoid trying to be clever.
There is a fourth insight, pertaining to build systems: Consistent, reliable incremental builds are unbeatable. The less often you do a rake clean the less time you lose.